Un TLFi simplifié
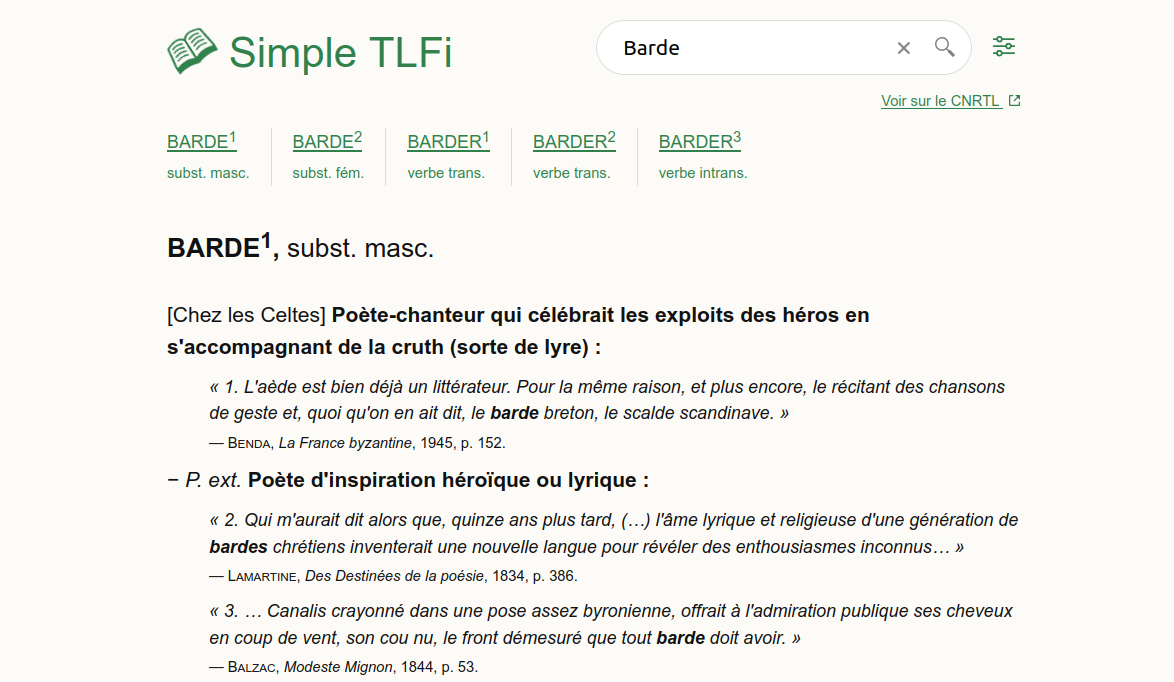
Pour faire court : j'ai créé une version simplifiée du dictionnaire principal du CNRTL, le TLFi. Elle se présente sous la forme d'une page épurée, accessible et adaptée aussi bien aux mobiles qu'aux ordinateurs. Un reformatage est effectué sur les définitions pour les présenter sous une forme plus lisible que l'originale.
Dans cet article, je parle un peu du pourquoi et du comment.
~
Si vous êtes cruciverbiste, si vous lisez des vieux livres pleins de mots désuets, si vous étudiez la langue française, ou si vous avez simplement déjà cherché la définition d'un mot dans Google, vous connaissez sans doute le CNRTL, le Centre National de Ressources Textuelles et Lexicales. Créé par un laboratoire du CNRS, il regroupe de nombreuses ressources informatisées autour de la langue française.
La partie la plus connue du site est son portail lexical, en gros un ensemble de dictionnaires plus ou moins spécialisés. Le premier d'entre eux, c'est le TLFi, le Trésor de la Langue Française informatisé (Wikipedia). Même s'il commence à dater et n'est plus mis à jour, ce dictionnaire est une ressource linguistique précieuse, pas seulement pour ses définitions mais aussi pour la richesse de ses annotations et ses nombreuses références littéraires. Il est également disponible sur son propre site, sous une forme assez complexe. Son incarnation sur le CNRTL est bien mieux référencée par les moteurs de recherche, donc plus connue.

Malheureusement, la consultation sur le CNRTL est assez compliquée aussi. Datant d'avant l'émergence du responsive web design, le site n'est pas prévu pour le mobile et y est quasi-inutilisable. Même sur un ordinateur, l'expérience n'est pas très claire, gênée par l'esthétique générale dans un style classique "labo de recherche" assez chargé. Le site est peu accessible, pas pensé pour la navigation au clavier et les lecteurs d'écran. Enfin, le contenu du TLFi est présenté de manière très brute, très liée à ses racines de dictionnaire papier, et exploite peu les possibilités de présentation du web.
Tout ceci n'est pas une critique. Le site n'a pas à rougir des standards techniques de l'époque où il a été mis en ligne. Et cet état de fait me paraît parfaitement normal pour une ressource mise à disposition gratuitement par un laboratoire public. À vrai dire, avec les contraintes que les gouvernements font peser sur la recherche depuis des années, ça me semble même un miracle que le CNRTL soit encore en ligne. J'y suis attaché et j'en suis un utilisateur occasionnel. C'est ce qui m'a poussé à voir si je ne pouvais pas lui offrir une interface plus simple et plus moderne.
Le projet
Au début, je pensais juste faire une feuille de style personnalisée qu'on pourrait appliquer au site. Mais en me familiarisant avec son code HTML, je me suis rendu compte que ce serait vite trop limité. Du coup, c'est devenu une petite application web à part entière avec son propre serveur en Node.js/Express.
Son code source est disponible sur GitHub.
La version "officielle" que j'ai déployée est attachée à ce blog mais l'application peut tourner toute seule, par exemple si vous voulez monter votre propre instance privée.

L'application se sert en gros du site du CNRTL comme d'une API. Plus exactement, quand on lui soumet un mot, le serveur effectue une requête au CNRTL pour obtenir la même page de résultat que sur le vrai site. Le contenu est trituré et simplifié grâce à Cheerio, une espèce de jQuery pour Node. Je ne porte pas cet outil dans mon cœur (l'API est confuse et ça fait mal de refaire du jQuery côté serveur après s'en être débarrassé côté client) mais c'était ce qu'il y avait de plus adapté au parsing bricolé des multitudes de formes bizarres qu'on trouve dans le balisage du TLFi.
À part ça, rien d'extravagant. C'est du pur rendu côté serveur, avec seulement quelques lignes de JS côté client pour améliorer l'UX. Je constate encore une fois que ça fait du bien de lâcher dès que c'est possible les architectures compliquées et les gros frameworks JS/CSS que j'utilise au boulot.
Le design
Côté design aussi je me suis fait plaisir. En m'inspirant du look déjà épuré de ce blog, j'ai fait un exercice de simplification radicale avec l'accessibilité et l'utilisabilité sur mobile en priorités… comme ça devrait l'être tout le temps.
Le chemin utilisateur se résume à un champ de recherche et un résultat textuel brut, qui affiche sur une seule page toutes les définitions homonymes, au lieu du système d'onglets peu visible du CNRTL. Le seul raffinement est une barre de navigation fixe (merci position:sticky) pour naviguer facilement entre ces homonymes, lorsqu'il y en a.
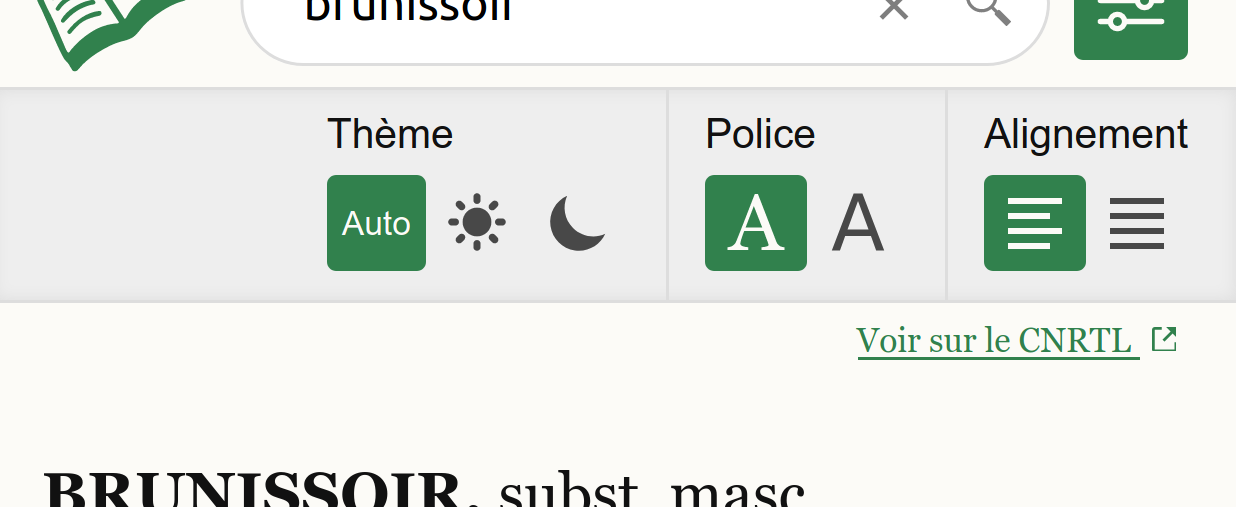
J'ai tout de même ajouté quelques options de configuration, en restant simple encore une fois. Quelques réglages typographiques et un thème sombre, activé selon les réglages de votre navigateur ou à volonté.
Le contenu
En ce qui concerne le corps des définitions, je me suis surtout concentré sur le formatage des citations littéraires. Elles forment la majeure partie du contenu du TLF mais me semblaient peu mises en valeur dans l'original. Le HTML se prêtant particulièrement bien à ça, je les ai rendues simples à distinguer du reste du contenu, correctement balisées et mises en forme de manière homogène.
Tout ça peut paraître trivial, un simple renommage de balises et quelques règles de style. Ce serait simple si la structure du contenu était stricte et fiable. Or, le TLFi provient en grande partie d'un travail de saisie manuelle, avec l'hétérogénéité et les erreurs que cela implique. Il y a bien sûr une constance dans la plupart des structures, mais d'une définition à l'autre, d'une citation à l'autre, on peut trouver des manières différentes de délimiter une source, de gérer les guillemets ou les italiques, de respecter la ponctuation, etc. Le contenu est un ensemble de cas particuliers difficiles à interpréter et parser.
C'est pourquoi, sur ma version comme sur le CNRTL, on trouvera de nombreuses incohérences ou des exemples de règles typographiques maltraitées (exemple : pas d'espace après un point). Hormis la mise en forme des citations et quelques substitutions typographiques triviales, j'ai fait peu de reformatage et le contenu est donc très proche de l'original. J'aurais aimé par exemple rediviser le contenu en vraies sections hiérarchiques, avec une numérotation automatique propre, mais je me suis perdu dans le nombre de cas existants et les noms de classe abscons.
Comme tout projet, on peut imaginer des tonnes d'améliorations. J'en apporterai peut-être certaines si je vois qu'il y a des utilisateurs et qu'on me fait des retours, mais je ne compte pas passer trop de temps à maintenir ce projet.
Et à ce propos…
Avertissement
Comme je l'indique en bas de chaque page de ce "Simple TLFi", cette application n'est qu'un petit projet personnel. Les points qui me paraissaient importants reflètent ma vision de dévéloppeur web certes attaché à la langue française mais plus encore à l'expérience utilisateur d'un site. Si ça se trouve, j'ai dénaturé certaines conventions d'affichage importantes du TLFi ou mis de côté des fonctions très utiles présentes sur le CNRTL. Je vous invite donc dans tous les cas à vous référer à la source originale en priorité car elle est bien plus riche.
J'ai envisagé ce projet comme un exercice pour voir ce qu'il était possible de faire pour améliorer l'utilisabilité d'un service connu en quelques heures de travail. Je pense que le résultat est assez intéressant pour être mis à disposition d'éventuels utilisateurs. Cependant, cette application est techniquement dépendante de l'état actuel du site du CNRTL pour fonctionner. Si ce dernier devient indisponible du jour au lendemain ou est subitement remanié avec une toute nouvelle architecture, l'application ne fonctionnera plus. Sachant que le CNRTL n'a pas été mis à jour depuis 2012, les deux options n'ont rien d'improbable…
Enfin, cette application simplifiée a recours à un procédé (le web scraping) qui est très discutable en terme d'attribution du contenu et d'utilisation des ressources d'un autre service. Je ne m'attends pas à avoir des millions de visite (et cette version ne sera pas référencée par Google), mais il n'est pas exclu qu'on me demande un jour de le désactiver.
Cependant, si vous êtes en lien avec le CNRTL, ça m'intéresse bien plus de parler avec vous de comment on pourrait améliorer le TLFi à la source :)