A map of Irish traditional tunes
After my morphing animation of historical Ireland maps, here is another little project involving Ireland and geography. And this time, it's also about music.
I'm not a musician myself, but my friend Anne-Sophie plays all kinds of Irish whistles. During a travel around Ireland last summer, we went to great pub sessions, listened to traditional music, and talked a lot about it. She explained to me some traditions associated to it ― the different types of tunes based on meter and how they are supposed to be danced, how musicians who have never met before can play together so easily, how sets are made up, etc. She also introduced me to The Session, a great website where Irish music players worldwide share and organize their knowledge in an open database.
An interesting point about this music is that a lot of tunes and songs have been and continue to be orally transmitted between musicians, inducing musical variations, intentional or not. Another thing that may change is the tune title. The same tune will be known under different names across the country.
At one point when looking at these titles, we realized a constant was that many of them refer to towns or other places. The Road to Sligo or The Killaloe Boat are really common name patterns. The idea of a map displaying these relationships between music and geography came naturally. By somehow crossing tune metadata from The Session with place names and locations, it was certainly possible.
The idea had been sleeping for some months, until I recently worked on it. Here is the result, as hosted by the Irish Association of Paris:
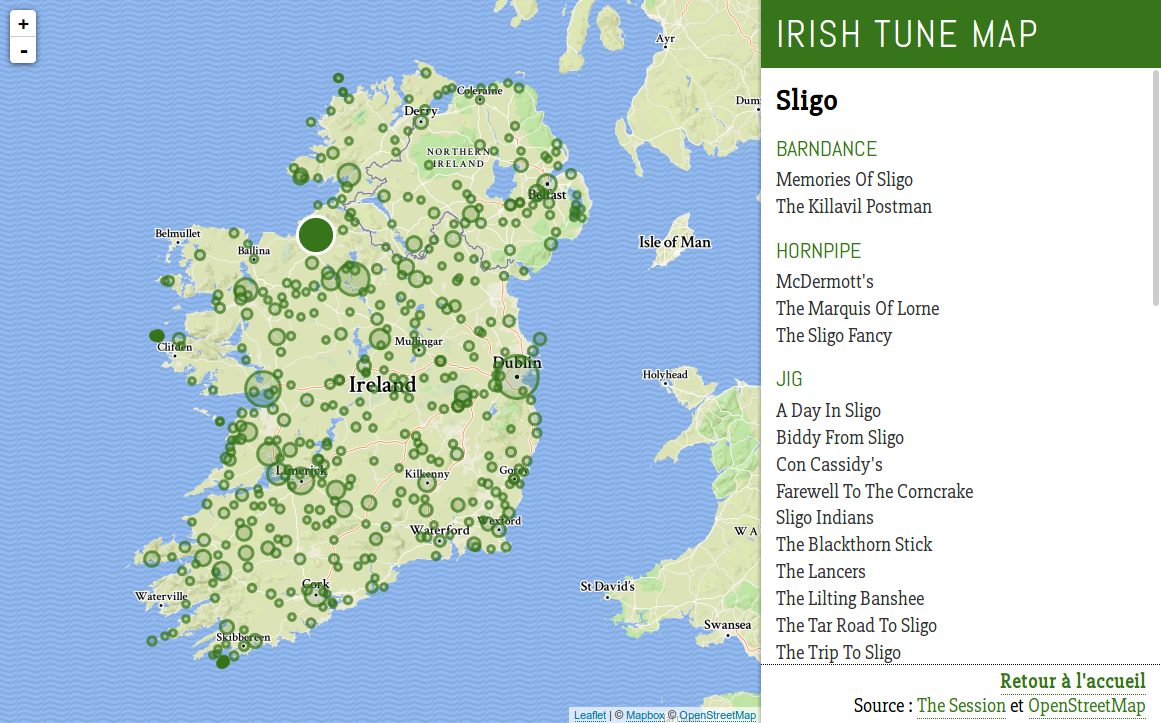
I put the whole project on GitHub, and here are some technical notes about the process.
Getting place data
For place data, I turned of course to OpenStreetMap. I wanted a list of Irish locations' names and coordinates, ideally in the GeoJSON standard format. For this kind of task, OSM offers an HTTP API named Overpass. It's more or less a read-only engine over the OSM database, using its specific query language. But despite a rather good documentation, it has a tricky logic and can be hard to master. Fortunalety, there is also Overpass Turbo, a graphical client which includes a query-building wizard. It helps testing and refining queries before real-world use, or for one-shot exports.
However, even with the help of Overpass Turbo, you still encounter a number of traps. OpenStreetMap is a wonderful thing that never ceases to amaze me, but working with its raw data means dealing with its very lax (one might say 'chaotic') data model. This looseness is the reason why it's possible to map literally everything in OSM, but it can be a burden when you just want to export a simple, unified data set. You have to learn a lot of exceptions, through a mix of doc reading and fail/retry.
Here are some of the cases I had to take into account in my query:
- Most places are mapped as points (nodes in OSM terminology), many as polygons (closed ways), some as both. Some are even multi-polygons (represented as relations), for example when a town territory spans multiple islands.
- Some sets of lines (non-closed ways) are tagged as places too.
- Some places don't have names.
- Some polygons tagged as
cityare higher-level administrative district boundaries, like 'Galway City', which encompasses 'Galway' itself as a distinct object. - OSM may include "historic" data, for example known boundaries of places centuries ago.
For now I used the following query, which addresses most of these cases. I only left the relation case behind, because it increased complexity for little benefit in the end result. The coordinates make up a rough polygon shape drawn around Ireland, to restrict the results to this area.
[out:json][timeout:60];
(
node
[!"historic"]
["name"]
["place"~"city|town|village|island"]
(poly:"54.38 -4.95 55.53 -6.15 55.37 -10.23 51.04 -11.25 51.56 -6.32");
way
[!"admin_level"]
[!"historic"]
["name"]
["place"~"city|town|village|island"]
(poly:"54.38 -4.95 55.53 -6.15 55.37 -10.23 51.04 -11.25 51.56 -6.32");
);
out body;
>;
out skel qt;
The query result is a GeoJSON FeatureCollection of mixed Point, LineString and Polygon features. At this point it is rather big, because it includes large geometries, and because Overpass doesn't filter attributes. So, each object includes its whole list of OSM tags, nested in a tags property. Most of them are of little use to us, like variations of the place name in too many languages (English and Irish Gaelic are the only ones useful), administrative details or notes from the cartographer. So I had to clean it up a bit.
During the prototyping phase, when working on a file manually downloaded from Overpass Turbo, I used the jq command-line processor for that task. But ultimately I wanted to have a standalone script doing the whole fetch-and-transform job, with the opportunity for more elaborate processing (for example, replacing polygon geometries by their center point). So I ended up writing everything in a single Node program: get_places.js.
I also declared a npm command to run it, so by running :
$> npm run data:places
…the script gets called, our place data are fetched from OSM, transformed, and written into data/places.json.
If you look at the script code, you may be perplexed by all these R.* instructions. Those are functions from Ramda, an all-purpose utility library. It's the equivalent of Underscore or Lodash, the big difference being that it relies on the paradigms of functional programming. We've been using it a lot at work and I really like it, especially on these data-transformation scenarios. I find it helps to write clean code, emphasizing composition of atomic operations and making main flows easy to read.
const transformGeoJSON = R.pipe(
R.prop('features'), // get the 'features' array
R.map(simplifyGeom), // apply 'simplifyGeom' to each feature
R.map(simplifyProps), // apply 'simplifyProps' to each feature
turf.featureCollection // rebuild a FeatureCollection
);
This is the transformation that is applied to our GeoJSON FeatureCollection. It's a single function, built by composing the arguments of pipe, which are functions themselves. Each one receives the result of the previous one as argument and returns a new object. The last one comes from the turf spatial processing library. At the end, simplifyGeom and simplifyProps are the only parts I need to worry about, and I can safely write them as elementary and pure functions.
It takes a little time to wrap your mind around Ramda, but I think it's worth a try.
Getting tune data
Compared to extracting place information from OSM, obtaining the raw tune data was much easier. The Session, besides being an invaluable resource for musicians, is also completely developer-friendly, with an open API. Even better, dumps of the database itself are published regularly. This is perfect for this kind of project.
Information about tunes comes in the tunes.json file. It includes a lot of attributes that we won't use, such as the musical key and the grid. So we need to apply basic filtering to just keep the name, the type (jig, reel, hornpipe, etc.) for basic classification, and the id to rebuild an url to the tune page on The Session.
There is another subtlety. As I explained, many tunes on The Session have multiple known titles, sometimes just spelling variants. We have to take them into account to maximize the chance of a tune to match a place on the map. Name variants are stored in a separate file, aliases.json. So we need to fetch this file too, and merge these aliases with the previous data.
Once again, I gathered each of these steps in a single script, get_tunes.js. It produces the data/tunes.json file and can be ran with this command:
$> npm run data:tunes
As it needs to download two files and perform more tranformation, the script ends up being a bit more complicated than the place script. But with Promise.all synchronizing the two downloads and Ramda breaking everything out in simple steps, it all remains pretty self-explanatory.
At the end, the data/tunes.json is an array of tune objects with id, type and an array of names.
[
…
{
"id": "11",
"type": "reel",
"names": [
"Boys Of Malin, The",
"Boys Of Mallin, The",
"Boys Of Mallow, The",
"Karen Logan's"
]
},
…
]
Matching tunes and places
This is the central part. Working from the results of the two previous steps, the goal is to obtain a single GeoJSON FeatureCollection of places with associated tunes, ready to use on the map. I implemented this step in a third script: merge_tunes_places.js
The main algorithm is rather dumb: for each place, loop on each tune and keep the ones that match the place. A tune matches a place if at least one of the place names appears in at least one of the tune aliases.
This is easy to implement, but very greedy. With more than 14000 tunes and 2000 places, this makes around 30,000,000 matching tests to perform. And each one of these checks has to loop on several name variants and perform a costly RegExp test each time.
A better, cleaner way to optimize this might be to use some kind of string indexing system, akin to the ones used in search engines. But that would be really overkill for this project. And there is no real performance issue here, it's only a one-shot process that doesn't need to run in realtime. It bothered me to have to wait minutes for the script to end though, so I looked for some easy tweaks. One efficient trick was to concatenate and store all the aliases of a tune in a single string. That way, many loops are spared and the matching check requires a single regular expression test.
const tuneAliases = [
'Miss Monaghan',
'Connacht Lasses',
'Stormy Weather',
'Shannon Shores'
];
const placeName = 'Shannon';
// The RegExp, accounting for word break
const containsPlaceName = new RegExp(`${placeName}(?:$| |,|')`);
// Bad: 4 tests will be performed
const matchesLoop = tuneAliases.some(alias => containsPlaceName.test(alias));
// 'Miss Monaghan ; Connacht Lasses ; Stormy Weather ; Shannon Shores'
const concatenatedTuneAliases = tuneAliases.join(' ; ');
// Good: a single test will be performed
const matchesConcat = containsPlaceName.test(concatenatedTuneAliases);
This script was also a good example of how using a lib like Ramda can affect your big picture of the process. Ramda implicitly encourages you to split everything into self-contained micro operations and to apply them step-by-step. It's quite addictive to structure a program this way, and can transform dirty code into one that is pleasant to read and test. But it's also easy to loose track of the induced overhead of all these loops and new instanciations. It's an acceptable, even invisible trade-off in most scenarios, but when working on large data sets and combinatory complexity, like here, it quickly backfires. My script isn't as "Ramda-esque" as it could have been, because I reverted some functions to a more traditional approach. As always, know your tools.
I also experienced more down-to-earth problems, the kind you always encounter when working on real-world geo data. Place homonyms, about which there isn't much I can do, and names that were too common, resulting in false positive matching. I solved the latter as much as I could, by creating a list of place names I simply ignore, like 'Abbey', 'Cross' or 'Street'. This is not perfect, but it helps avoiding putting huge markers on small villages, referencing tunes that are really about some random abbey or street.
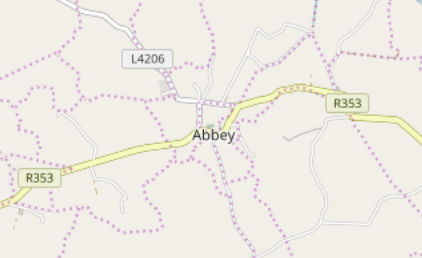
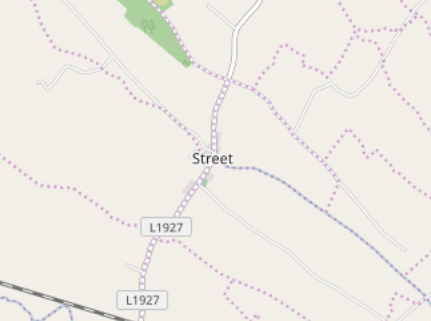
I declared another npm command for this script, 'data:merge', and 'data:all' which will call the two others before executing this one.
$> npm run data:all
At the end, we have a new GeoJSON file of Point features, each with an array of tunes associated to it:
{
"type": "Feature",
"id": "way/4557100",
"properties": {
"name": "Green Island",
"place": "island",
"tunes": [
{
"id": "9440",
"type": "jig",
"names": [
"Paddy's Green Island"
]
},
{
"id": "9535",
"type": "hornpipe",
"names": [
"Green Island, The",
"OLd Hornpipe From Winner's"
]
}
]
},
"geometry": {
"type": "Point",
"coordinates": [
-5.6142354999999995,
54.4618465
]
}
}
Unfortunate places that have no tune to celebrate them were simply removed. Our data are ready to be displayed.
The map
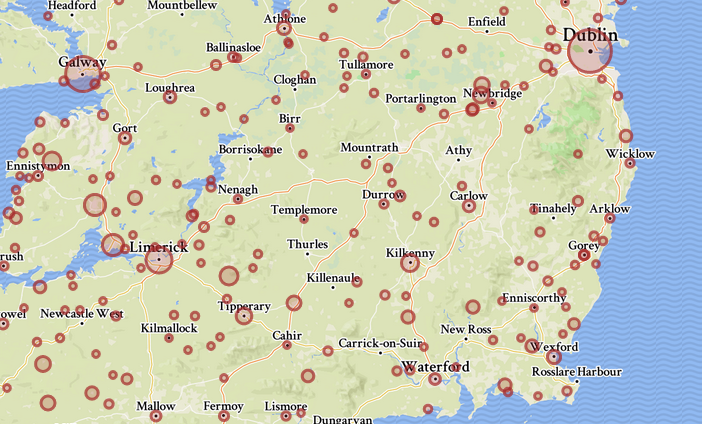

It's the easier part, nothing much to say really. Consuming and customizing GeoJSON layers in Leaflet is a breeze. I decided to display the places as circle markers, so no icon was needed and their size could be easily adjusted depending on the number of tunes linked to the place. For the background, I used a lazily customized Mapbox map style.
The rest is just formatting and displaying the list of tunes, grouped by type as it's useful information for musicians. The names in the list simply link to their tune pages on The Session.
I couldn't resist using Ramda in the client app too. Once again, I found it convenient for the definition of small util functions…
const placeName = R.path(['properties', 'name']);
const placeTunes = R.compose(R.defaultTo([]), R.path(['properties', 'tunes']));
const nbTunes = R.compose(R.length, placeTunes);
const tuneName = R.compose(R.head, R.prop('names'));
… or for data flows…
const formatTuneList = R.pipe(
R.sort(compareTune),
R.map(formatTuneListItem),
R.prepend('<ul>'), R.append('</ul>'),
R.join('')
);
But nothing too serious.
I didn't bother with module import, bundling and the like. Toy projects where you don't need to are a relief. So the three dependencies (fetch, Ramda and Leaflet) are fetched from CDN. I just used the ES6 syntax, because it's a pain not to do it now. So you need a Babel transpilation, but that's all.
Next?
As always with these quick projects, you get a working version in a relatively short time, and then you can spend the rest of your life improving and polishing it. There are a lot of possible improvements here.
The first one would be to remove some duplicates caused by odd data that I didn't process specifically. I'd also like to refine the OSM data selection and the matching logic, in part to include other types of place names. There are certainly songs about lakes or mountains.
I could also add features on the map itself. I like the result straightforward as it is: just explore the map, click it, that's it. But a place search form would be nice, and not hard to do. Lastly, the way tunes are displayed could also be improved. It may be interesting for example to show which tunes are linked to another place under a different alias.
Maybe you also have some suggestions?
Thanks for reading!